Overview
This post covers the core concepts that power modern language models:
- Natural Language Processing (NLP)
- Tokenization
- Word representation
- Word2Vec
Natural Language Processing (NLP)
Natural Language Processing is a computer science field focused on manipulating text with computational resources. Basically, it’s about teaching computers to understand and work with human language. At a high level, NLP tasks can be distinguished into three main fields:
Classification
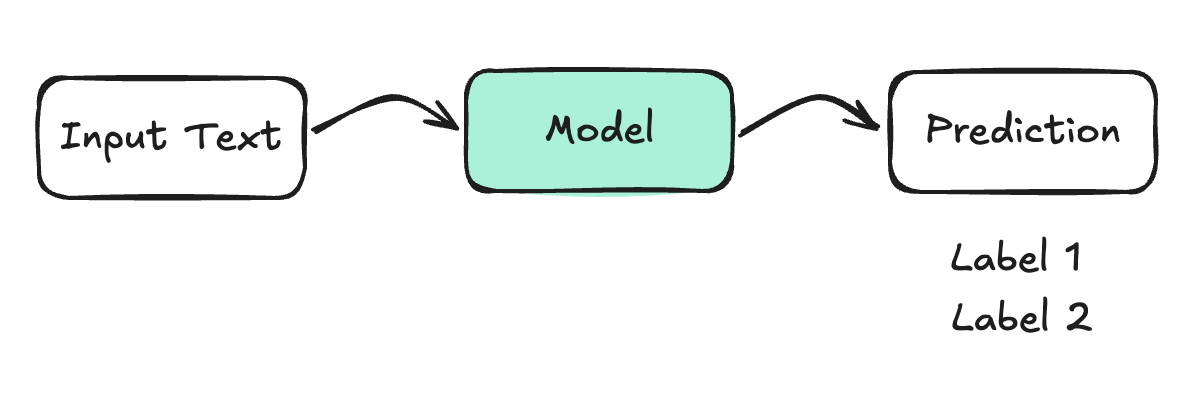
The model assigns a single label to the input text from a fixed set of categories. It chooses one category that best matches the text.
Example: Sentiment Analysis
"Today is such a beautiful day" → Model → "positive sentiment"
Datasets
Classification datasets are annotated by humans and used for training. This means people read the text and label it, so the model can learn:
- Twitter sentiment datasets
- Hate speech detection datasets
- Amazon product reviews
Evaluation Metrics
When datasets are imbalanced (unequal distribution of classes), you need evaluation metrics that account for this imbalance. These metrics help you understand if your model is actually working well:
- Accuracy: % of observations that were correctly predicted
- Precision: % of predicted positive cases that were actually correct
- Recall: % of actual positive cases that were correctly identified
- F1 Score: Harmonic mean of precision and recall (useful for imbalanced datasets)
Multi-Classification such as Sequence Labeling
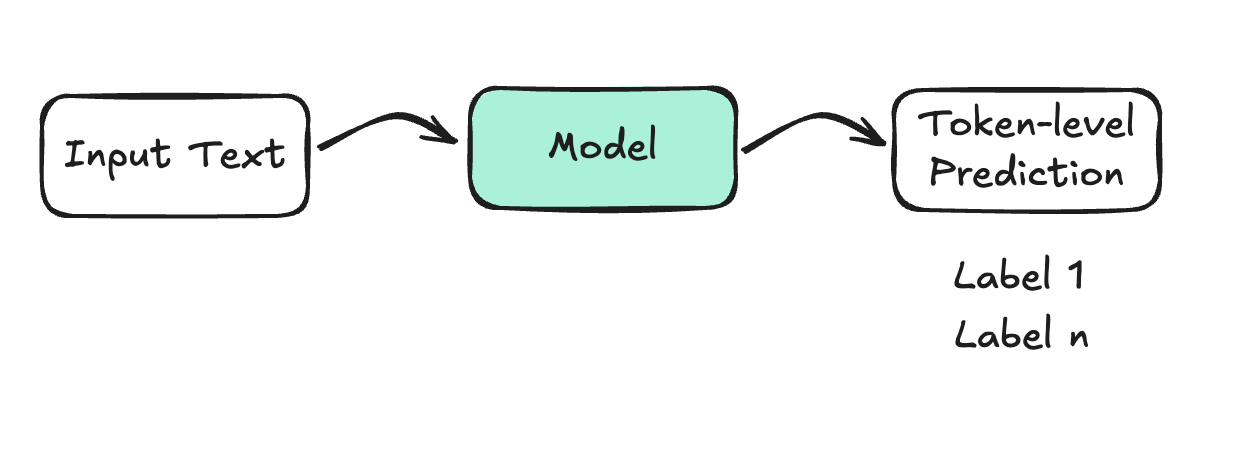
The model assigns a label to each token (or word) in the input. Instead of one answer for the whole text, it labels each word individually.
Example: Named Entity Recognition (NER)
"My name is John Doe" → Model → Entities: (Person: John Doe)
This identifies linguistic units like persons, locations, organizations, etc.
Datasets
Sequence labeling datasets contain pre-annotated entities. Annotators carefully mark each word to show what type of thing it is:
- Reuters news corpora (CoNLL-2003)
- Wikipedia-based datasets
- Domain-specific annotated corpora
Evaluation
Evaluation happens at the token level and is often computed per entity type. This shows how well the model labels individual words:
- Accuracy: % of tokens that were correctly labeled
- Precision: % of predicted entities that were correct
- Recall: % of actual entities that were correctly identified
- F1 Score: Harmonic mean of precision and recall
Generation
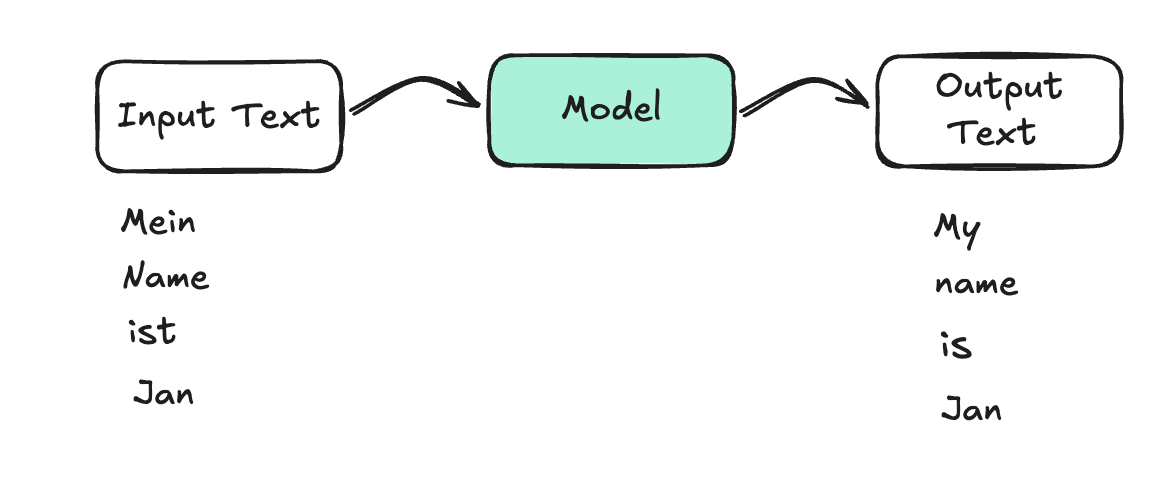
The model generates new text, which may be different in length from the input. The model creates something new that didn’t exist before.
Examples:
- Machine translation: “Heute ist ein schöner Tag” → “Today is a nice day”
- Question answering: “What is the capital of France?” → “Paris”
Datasets
Generation tasks use paired datasets. These contain matching pairs of input and output examples so the model can learn the relationship:
- WMT14 (English-to-French, English-to-German translation corpora)
- SQuAD (question answering)
Datasets and Models
In practice, very few people train language models from scratch. Instead, we build on top of existing building blocks provided by platforms like Hugging Face.
Data is available on Hugging Face: huggingface.co/datasets
Additional to larg amount of dataset, Hugging Face hosts thousands of pre-trained models like:
- BERT (understanding text)
- GPT-style models (generating text)
- T5 (text-to-text tasks)
- RoBERTa, DistilBERT, and many variants
Each model is already trained on massive text corpora and has learned:
- language structure
- word relationships
- basic semantic patterns
Models are available on Hugging Face: huggingface.co/datasets
Tokenization
How do models work with text? Neural networks operate on numbers, integers, floating-point values. For text, we need a way to convert human language into numbers. Given the vast vocabulary across languages and word variations, this isn’t trivial.
The Challenge: How do we represent “run,” “running,” and “runner” meaningfully to a model?
There are three main tokenization approaches:
Word-level Tokenization
Each word becomes a single token.
Example:
Text: "I love machine learning"
Tokens: ["I", "love", "machine", "learning"]
Token IDs: [15, 892, 4312, 2145]
Advantages
- Intuitive and easy to understand
- Words often correspond to meaningful concepts
Disadvantages
- Very large vocabulary size (100k+ tokens for English alone)
- Cannot handle unseen words encountered at inference time
- Different forms of the same word get unrelated IDs (“run” ≠ “running” ≠ “runner”)
Character-level Tokenization
Each character becomes a token.
Example:
Text: "Cat"
Tokens: ["c", "a", "t"]
Advantages
- Tiny vocabulary (~100-1000 characters across all languages)
- Can handle any language without modification
- Automatically processes new or misspelled words
Disadvantages
- Sequences become very long (e.g., “internationalization” = 20 tokens)
- Harder for the model to learn meaningful word-level patterns
- Computationally inefficient
Subword-level Tokenization
Modern language models use subword tokenization, which breaks words into smaller, reusable pieces.
Common algorithms:
- BPE (Byte Pair Encoding) — used by GPT-2, GPT-3
- WordPiece — used by BERT
- SentencePiece — used by many multilingual models
Example:
Text: "unhappiness"
Possible tokenization: ["un", "happi", "ness"]
The tokenizer learns these frequent subword units from large text corpora.
Advantages
- Smaller vocabulary size (30k-50k tokens typical)
- Handles unseen words efficiently—even if “chatgptization” never appeared in training, the tokenizer can break it into [“chat”, “gpt”, “ization”]
- Efficient sequence lengths (fewer tokens than character-level)
What Modern LLMs Use
Models like GPT, Claude, Gemini, Llama, and Mistral all use subword tokenization because it provides the best balance between vocabulary size, sequence efficiency, and generalization.
Typical Pipeline:
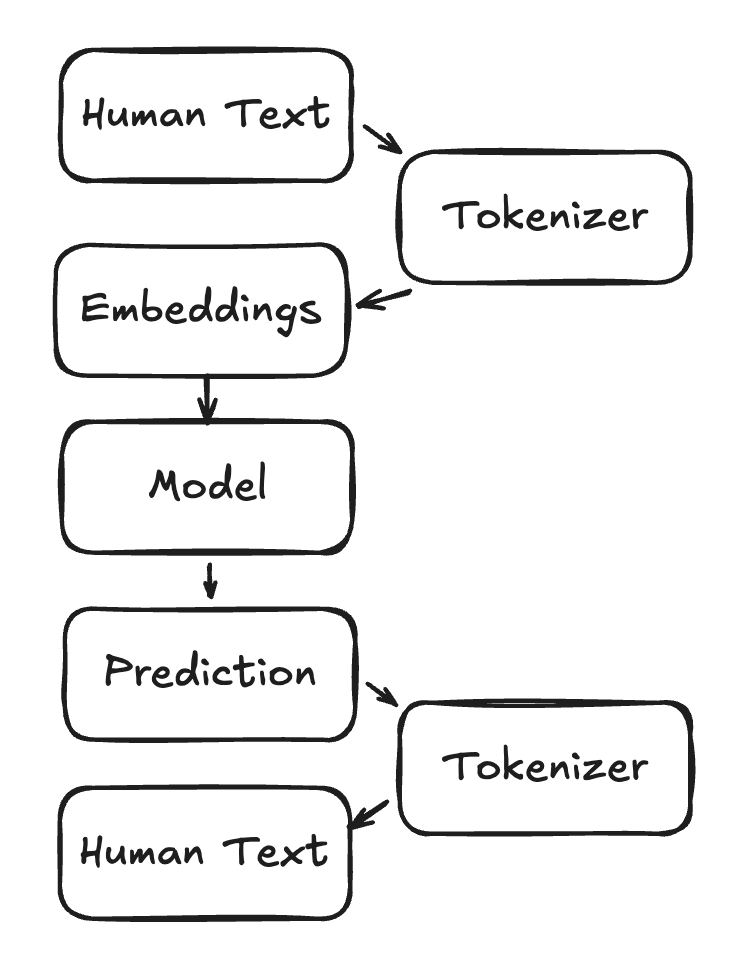
Overall you can say, tokenization is the bridge between human language and the numerical world that neural networks operate in.
Word repensentation
Now that we have token IDs, we need to represent them as meaningful vectors that a neural network can learn from.
Goal: Create representations where similar words are close to each other in vector space, and dissimilar words are far apart.
Example:
"cat" → [0.1, 0.54, 0.2, ...]
"dog" → [0.09, 0.52, 0.19, ...] (similar to "cat")
"car" → [0.8, 0.1, 0.9, ...] (different from "cat")
You can measure similarity using cosine similarity or other distance metrics. Tokens that appear in similar contexts should have similar vectors.
How Do We Learn Embeddings?
Embeddings are learned from data, not hand-crafted. Word2Vec is a foundational technique that demonstrates this principle.
Word2Vec
Word2Vec is a neural network trained on a self-supervised task: predict words based on context. It learns embedding representations as a byproduct.
The Two Approaches
-
CBOW (Continuous Bag of Words): Predict a word given its surrounding context
Input: ["the", "quick", "brown", "_____", "jumps"] Predict: "fox" -
Skip-gram: Predict the surrounding words given a single word
Input: "fox" Predict: ["the", "quick", "brown", "jumps"]
How Word2Vec Works
Word2Vec is a simple 2-layer neural network:
- Input Layer: Text is represented as one-hot encoded token IDs
- Hidden Layer: Contains N neurons, where N = desired embedding dimension (e.g., 300)
- Output Layer: Predicts the target word (produces probability distribution) The magic happens during training: the weights in the hidden layer become the word embeddings.
After training:
- Similar words like “king” and “queen” are close in vector space
- The model learns semantic relationships:
king - man + woman ≈ queen - Word vectors capture syntactic and semantic information Architecture Visualization:
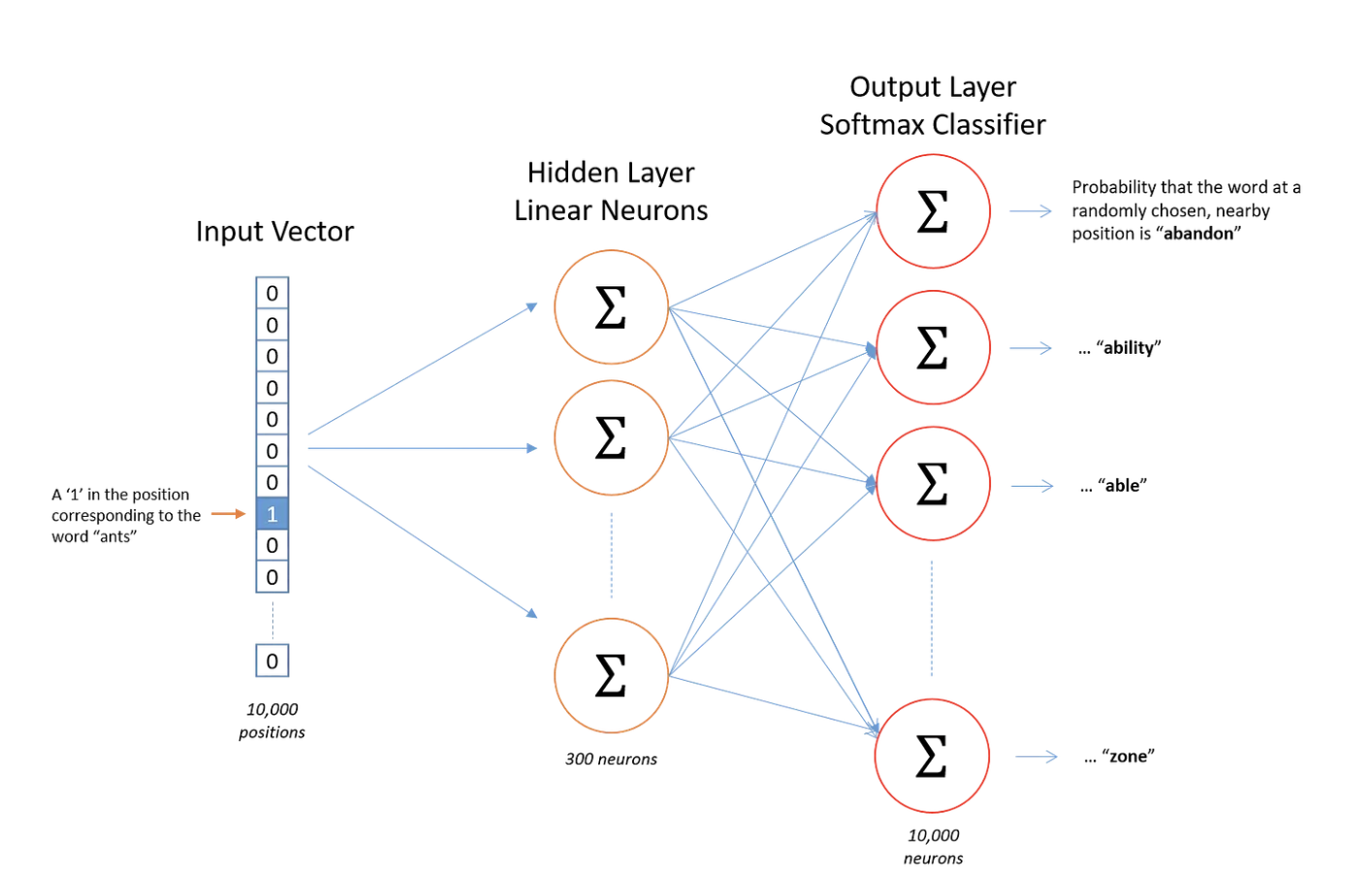
Key Training Concepts
- A Positive Examples is a Word that actually appear in context (label = 1)
- Negative Sampling is Random words that shouldn’t be predicted (label = 0)
- The Loss Function is Binary classification loss (word belongs in context or not)
- Hidden layer weights become the final embeddings
Summary
These three concepts form the foundation of how language models process text:
- Tokenization bridges human language and numbers
- Embeddings capture semantic meaning in vector space
- Word2Vec shows how to learn meaningful representations from raw text
Modern language models build on these fundamentals, using more sophisticated tokenization, more advanced embedding techniques (contextual embeddings like those in transformers), and larger-scale training. But the core principle remains: convert text → tokens → vectors → predictions. In the next blogs post we will dive deeper into attention and transfomer architectures.
If you want to dive deeper into how modern LLM work, i am working on a second blog